Stable Diffusion的部署、训练和使用
Stable Diffusion的部署、训练和使用
AI图像生成最近所展现出的潜力可谓是让人大开眼界,它能够从一些简单的文字描述开始,变魔法一般的变出高质量的图片。不用说,这已然深刻的拓宽了人类创作艺术的方式。
而其中,Stable Diffusion的公布算是一个里程碑事件了,它的开源不仅仅意味着面向大众群体公开了一个极高质量的模型,与此同时这个模型甚至能保持很快的运行速度和较低的显存需求。
本实践借助Stable Diffusion整合的webUI界面以及云平台,通过实际部署、调试、使用,具体切实地感受影响图像生成的因素以及相关的机理。
一.概述
(1)设备及相关环境配置
①机型:
惠普Laptop - 14s - dr2002TU
②云GPU算力服务器平台AutoDL:
CPU :15 核心
内存:80 GB
GPU :NVIDIA GeForce RTX 3090, 1
存储:
- 系 统 盘:25G
- 数 据 盘:50G
③相关环境配置:
Python:

Pip:
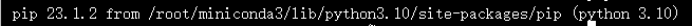
Cuda:
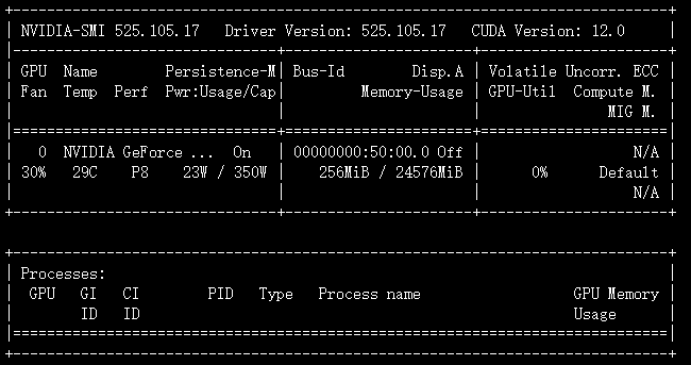
(2)实验步骤;
- 模型部署 - 模型训练 / 调试 - 实际使用
二.操作描述
(一)操作过程
1. 服务器申请及环境搭建
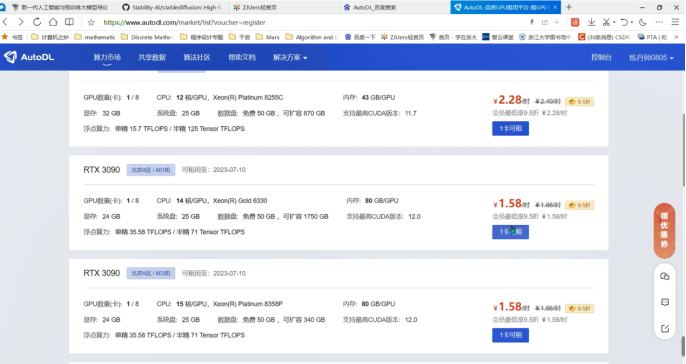
①在AutoDL平台注册完成之后,就可以开始选择所需的GPU
为了完成本次实验,租用一张RTX3090时长3h即可
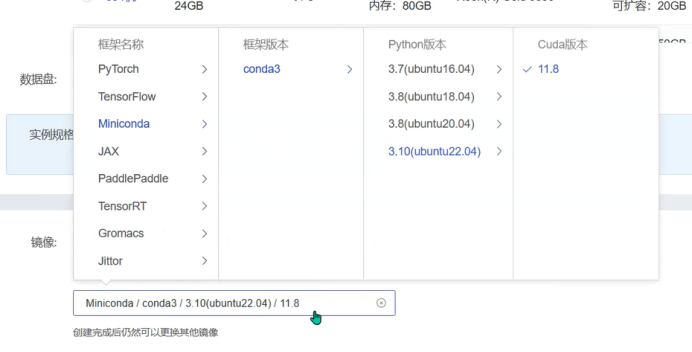
②点击
“一卡可租”后进入租赁界面进行属性选配此处有一步骤相当关键,就是此处的相关框架、Python、Cuda版本的选择,因为Stable Diffusion 的部署有相当严格的要求,务必按图示中选择
③在
“容器实例”处,可以看见我们刚刚租赁的实例,点击“JupyterLab”,进入交互式编程界面,进行模型的部署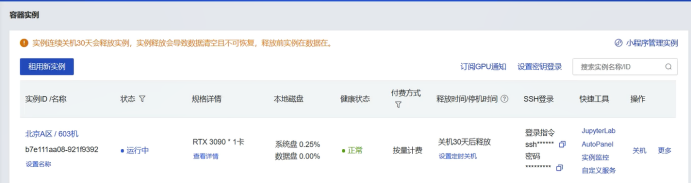
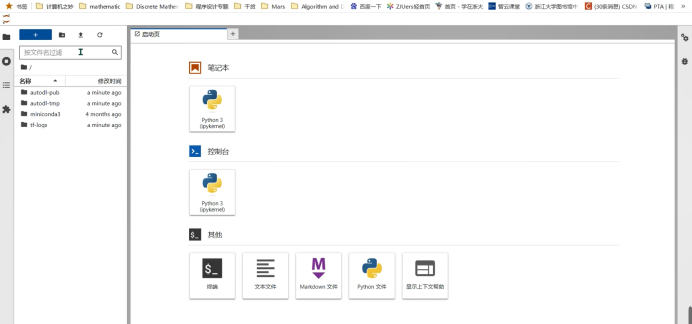
2. Diffusion的部署
①下载Stable Diffusion web UI
在终端中输入以下命令,这里部署在了数据盘而不是系统盘,因为后续还需要下载各种模型,占用空间较大。
1
2
3git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
# 如果连接超时,需要多试几次,因为git的连接有时很不稳定。②尝试运行Stable Diffusion
下载完成后,进入项目根目录,执行命令:
1
2
3
4
5
6
7
8cd stable-diffusion-webui
COMMANDLINE_ARGS="--medvram --always-batch-cond-uncond --port 6006" REQS_FILE="requirements.txt" python launch.py
# 其中launch.py是执行脚本,medvram和always-batch-cond-uncond都是显存优化的参数;
# port 6006指定进程运行在机器的6006端口上。因为autodl自带了一个对外暴露的服务,端口号为6006,所以这样设置。
# 最后的REQS_FILE是运行所需要的的依赖,命令执行后会自动安装依赖。
# 本次实验中,自动安装依赖成功,但假如始终出现超时,就要通过手动下载再move相关文件进行依赖安装
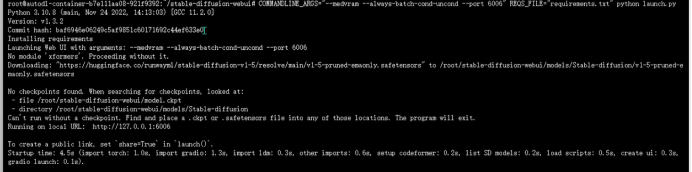
③所有依赖安装完毕后,在项目主目录下再次执行命令:
1
COMMANDLINE_ARGS="--medvram --always-batch-cond-uncond --port 6006" REQS_FILE="requirements.txt" python launch.py如果出现以下输出则表示运行成功:
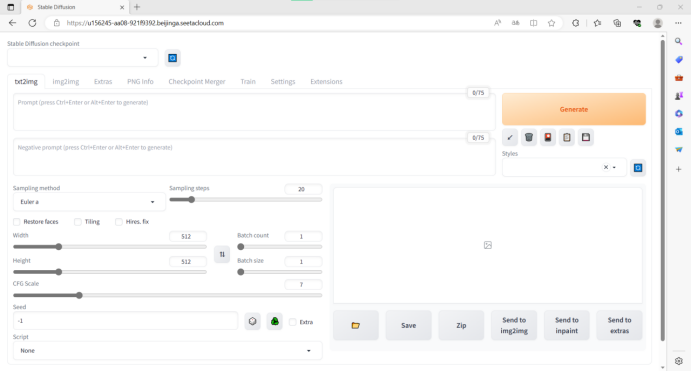
我们接下来回到实例列表处,点击
“自定义服务”,便可以在6006端口运行的时候以此为入口打开相应的网址
即可在浏览器中打开Stable Diffusion 的WebUI界面
3. 模型的训练/调试
①点击菜单栏的
“Train”选项,先进入“Create Embedding”(嵌入)模块,填入该模型的名称以及初始化名字(即调用模型时候所用的语言)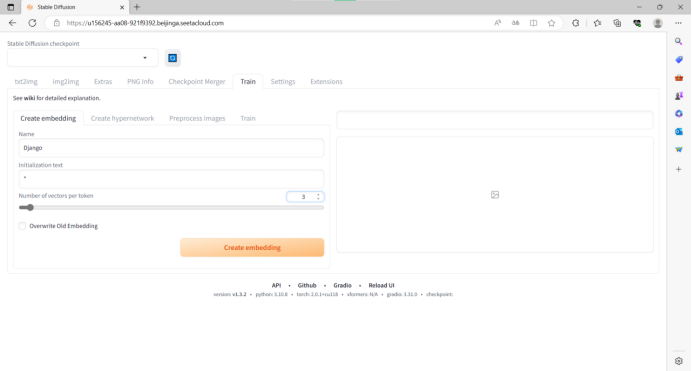
再进入
“Preprocess images”(图像预处理)模块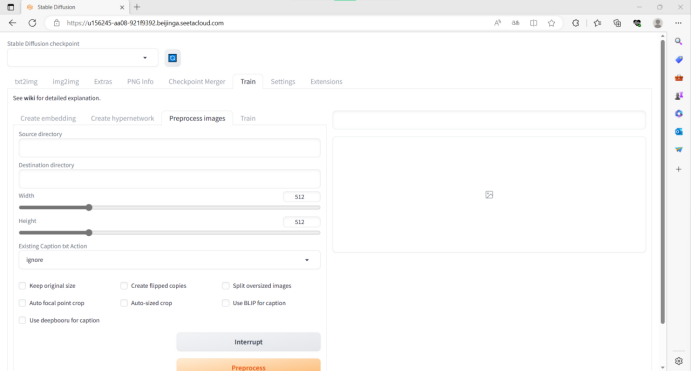
②然后就需要我们将图片进行预处理
最好找头像清晰的,脸部轮廓清楚的,背景最好是白色的
先将图片放在一个文件夹里,然后定一个预处理之后的文件夹名字
按照说明,填入预处理图片路径和目标目录,然后选择
“Deepbooru”生成标签然后点击
“Preprocess”,等处理完成。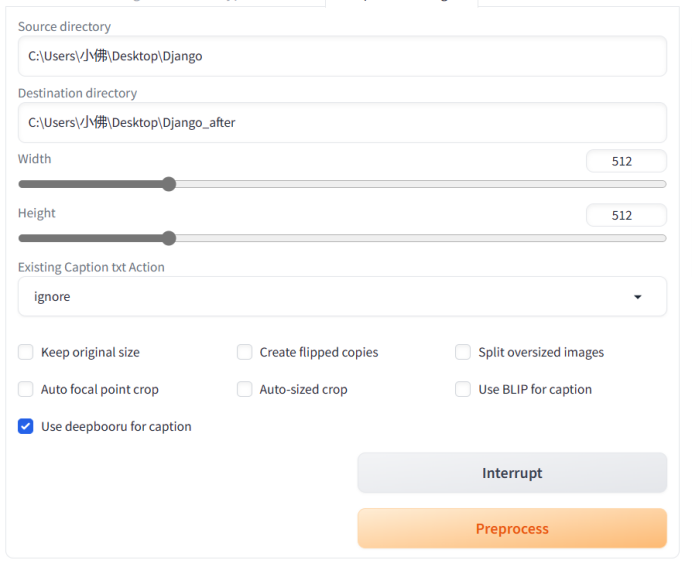
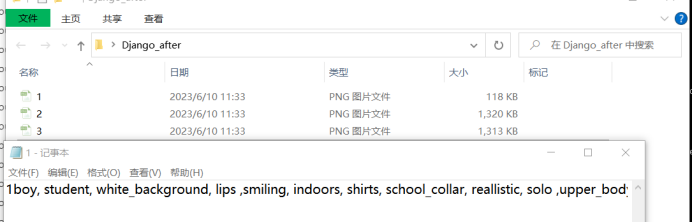
③到目标目录下,看下生成的标签信息
由于某种原因,这张图片打上了厚码(

④点击
“Train”模块,点击训练,在Embedding处选择刚才建立的Django文件填写Dataset directory(刚刚的目标数据集文件夹路径)
Prompt template选择默认的即可
在最下方点击
“Train Embedding”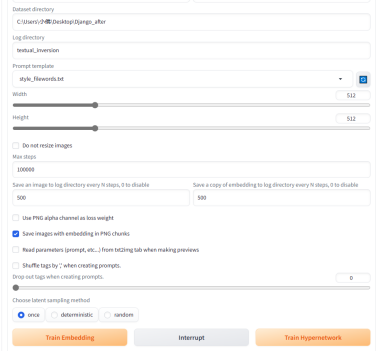
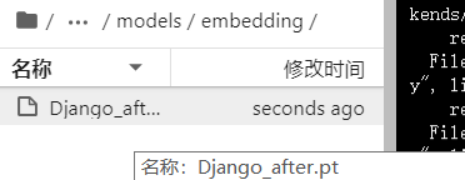
⑤模型正在训练,每过一段时间会展示出最新的预览图,在觉得可以的时候点击
“interupt”即可结束训练后,可以在stable-diffusion-webui/models/embeddings里面可以找到已经训练好的模型:Django_after.pt
4. 模型的使用
进入到Stable Diffusion的 WebUI界面,点选右上角
“Generate”按钮下面的“Show Extra Networks”按钮会出现文本反转textual inversion、超网络、lora这些按钮,点击右边的
蓝色按钮,刷新一下,就可以看到Django_after的textual inversion模型了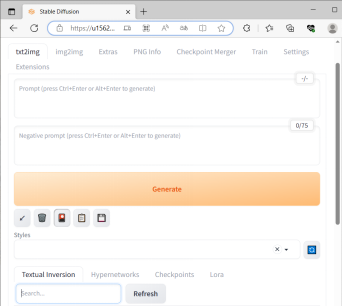
在提示词输入框里面输入提示词,比如:a boy reading a book in library,然后点击刚才的模型的pt文件,这就会调用刚才生成的模型,然后点击生成图片的按钮,生成效果如下


显然训练的效果不是很好……
(可能 3.⑤interrupt得太快了,还需要进行调整)
三.进入过的误区
No matching distribution found for….
报错原因:
pip等级过低/网络问题需要换国内源
改进方式:
①
python -m pip install --upgrade pip进行升级②
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.douban.com使用国内镜像站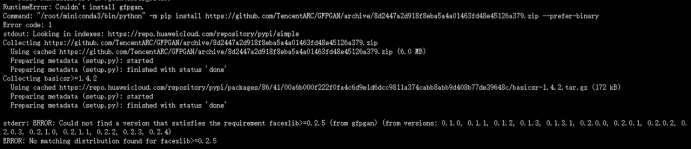
结果:
可以正常运行
四.回顾与心得:
实践存在遗憾,就是由于电脑配置的原因,不得不借助云平台进行部署。这过程中有诸多的不便,例如网络上在git拉取上的一些波动,以及相关环境的配置。同时虽然每小时只需一块五,但仍然让人有紧迫感,训练模型等雁过无痕,相应的结果自然有些潦草失真。
即使能够本地部署这样一个大模型,算力仍然是限制图形质量高低的一个重要的因素。所以在建模方面,我明白有多种建模方式例如lora、dream booth等等,但我还是选择了Textual Inversion (Embedding),其优势在于模型文件非常小,操作也是比较简单的,但是效果明显不如dream booth,而且训练耗时时间较长(不过本次实验中我跳过了深度的训练)。使用者的评价多为:综合起来看,训练Lora模型对于大部分人来说可能更好。尚未试过,也不做评价了。
而随着部署了Stable Diffusion ,我也发现了这样能够部署在个人电脑上的大模型,在内容生成的监管上存在着很多讨论的空间。如何限制人们运用AIGC生成一些“不太好”的内同(或者要不要限制),这是一个值得探讨的问题。本地部署大模型带给了我们安全性、自由度,但我们又需要做些什么?……